
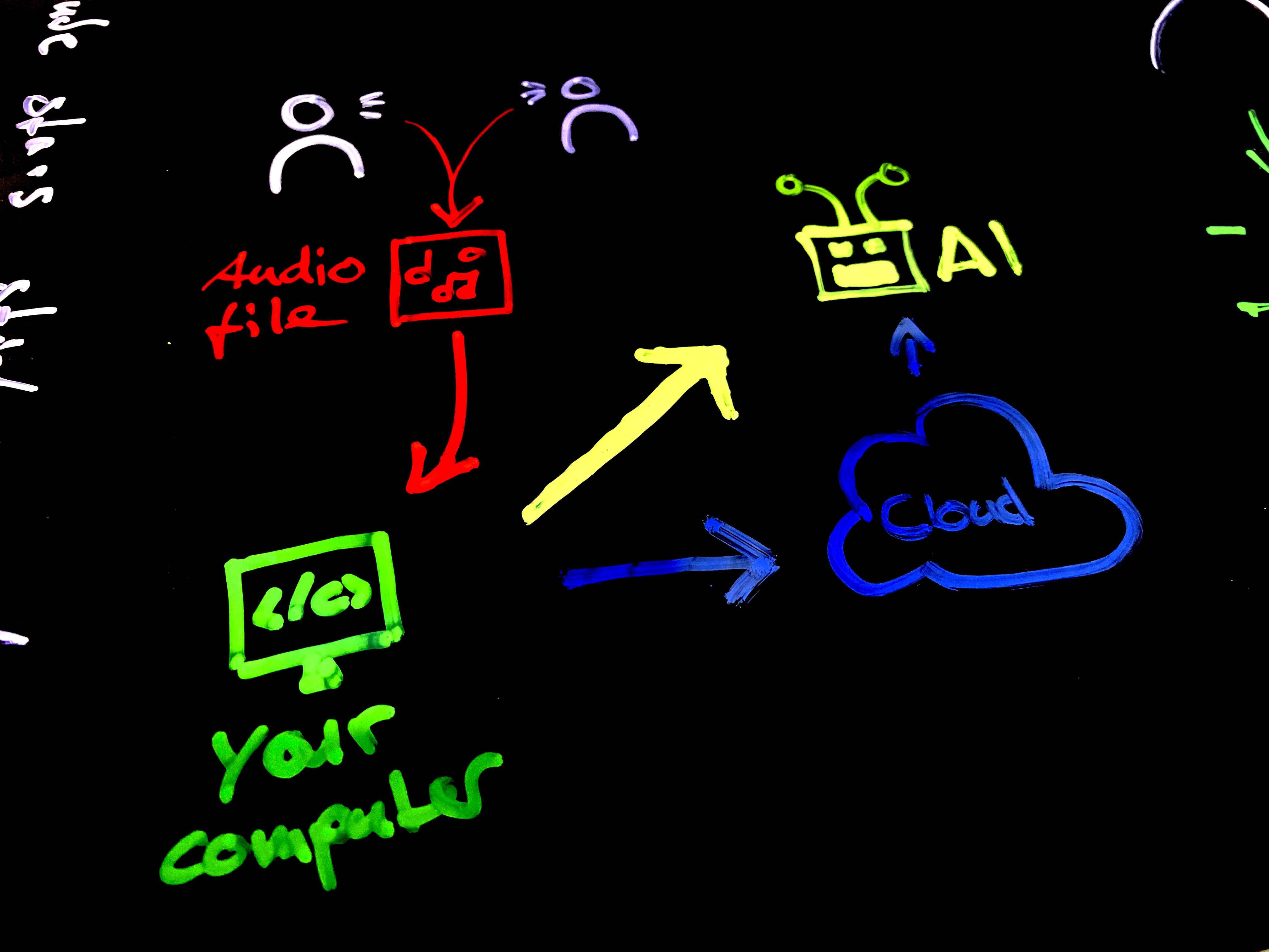
About a week back I had a casual chat with one of my friends and it turned out that she’s facing a problem that a lot of students will probably come across in their studies: Transcribing interviews.
| # | Chapter | Importance |
| 1. | Set Up your dev environment | required |
| 2. | Open your Terminal | required |
| 3. | Install Cloud related libraries | required |
| 4. | Create a project in the Google Cloud | required |
| 5. | Authenticate your machine with the Cloud | required |
| 6. | Create a short audio file | required |
| 7. | Create a python file | required |
| 8. | Run your code | required |
| 9. | Monitor requests to the API | optional |
| 10. | View the result of your request | required |
| 11. | Create a Google Cloud Storage Account | optional |
| 12. | Upload file to Google Cloud Storage | optional |
| 13. | Run the Script by providing the new location | optional |
| 14. | Debugging & Error Messages | optional |
To me this sounded like a solved problem and I was sure that there are some free services out there that could just do this for her but it turned out to be harder than I thought. It seems like there are 3 ways of getting a spoken interview transcribed:
- listen to the interview and type it off by yourself
- hire someone who transcribes the interview for you
- have a machine to the job for you
The last sounded like the most sane solution to the problem and so I looked up some existing software that is out there that tackles this issue. Unfortunately this is an expensive problem to solve. Its either time intense (manually typing), cost expensive (to hire someone or use a tool) or computing intense (which results into cost expensive).
This makes all software (I found) out there expensive since a well trained machine learning model has to run on high performing hardware to get the spoken language into text. Most services will offer some free tier solution, where 1 min is free until you get charged (freemium model). The audio files from my friend have been >30min and longer and splitting it up into small chunks to get around the limitation was neither ethical nor a fun task.
The solution: Google Cloud Speech API
During my five minute research I came across the Google Speech to Text API and the connected Google Cloud Services. On their Speech Service overview page Google describes how they are able to take audio files of any length, run a machine learning model on it that is trained to turn speech into text and deliver results fast and free (up to 60 minutes) for a set of over 120 languages.

The linked documentation looked easy to handle and well detailed for beginners. The quick start guides promised an easy to handle process and I’ve already seen the finished product in front of my eyes. Nevertheless I ran into some issues for my specific case because I rather used the wrong API endpoints or a wrong method of submitting my file. On top of that, my development environment was poorly setup due to a recent machine upgrade.
Here is a step by step guide about how you can turn an up to 1h long audio file into text completely for free (charges apply if your file is longer but the system will be able to process that).
1. Set Up your dev environment
Since I’m familiar with python, I used that language to accomplish my task. Even if you have little to no knowledge about programming, this tutorial got you covered. First of all:
Install Python (I advise 2.7.9 or 3.7.0) by downloading it from this website: https://www.python.org/downloads/
2. Open your Terminal
On Mac, use the shortcut COMMAND + SPACE to open spotlight. Then search for “Terminal”, press enter.

On Windows, click the ‘Start’ -> Program Files -> Accessories -> Command Prompt to open the command line.
3. Install Cloud related libraries
Now with the terminal open, copy the code below, paste it into the terminal and press enter. This will download the required libraries. In case you have two different python versions installed (some macos versions come with python 2.7 pre installed), you have to run the below line by turning ‘pip’ into ‘pip3’.
pip install --upgrade google-cloud-speechYou might need the following library during the process so run this line as well:
pip install gcloud4. Create a project in the Google Cloud
Make sure you have a Google Account and register for the Google Cloud services. You will be asked to enter a credit card (you won’t be charged if you stay within the free tier) and your address along some other personal information. You should now be able to access the Google Cloud Console. In there, create a ‘new project’ and give it any name. If you can’t find the ‘Create Project’ Button in the account, check here: Google Cloud Quick Start
5. Authenticate your machine with the Cloud
You are required to send an authentication file to the Google Cloud so that your SDK gets initialised. You do this by downloading the json blob that you received during the project setup. Store this file on your desktop. Now run the following lines in your terminal (make sure you replace ‘filename’ with the actual file name):
cd desktopexport GOOGLE_APPLICATION_CREDENTIALS="filename.json"In the windows command prompt you have to run the following line
set GOOGLE_APPLICATION_CREDENTIALS=filename.json6. Create a short audio file
In order to run some tests, I highly recommend testing with a small file rather then going straight ahead with a big and long file. For testing purposes, you can use this file saying ‘hello world’. Save it on your desktop.
7. Create a python file
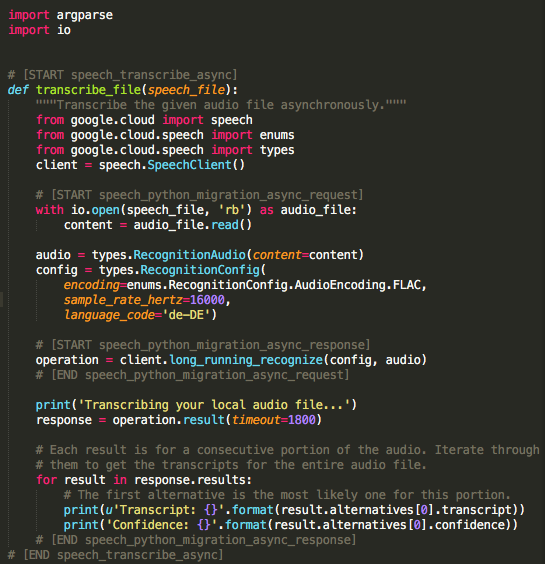
Google provides a file that is filled with test code that you can instantly run in order to get your file transcribed.
Open a text editor or a program like Sublime Text 2, paste the sample code from this page (all 102 lines) and safe the file under GoogleSpeech4.py on your desktop.
In the code, adjust the following values to what fits’s to your audio file:
- language_code (set it to en-US for english, de-DE for German, fr-FR for french, …)
- sample_rate_hertz (this needs to match the sample rate of your audio file)
- timeout (set it to 90 seconds for testing and turn it up for bigger audio files
#!/usr/bin/env python
# Copyright 2017 Google Inc. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Google Cloud Speech API using the REST API for async
batch processing.
How to use:
python GoogleSpeech4.py Filename.flac
python GoogleSpeech4.py gs://gsfiles/filename.flac
Upload file to https://console.cloud.google.com/storage/browser/gsfiles?project=second-form-228820&folder&organizationId=1062515115803
Adjustments by Julian Redlich (please@rankmeamadeus.com)
"""
import argparse
import io
# [START speech_transcribe_async]
def transcribe_file(speech_file):
"""Transcribe the given audio file asynchronously."""
from google.cloud import speech
from google.cloud.speech import enums
from google.cloud.speech import types
client = speech.SpeechClient()
# [START speech_python_migration_async_request]
with io.open(speech_file, 'rb') as audio_file:
content = audio_file.read()
audio = types.RecognitionAudio(content=content)
config = types.RecognitionConfig(
encoding=enums.RecognitionConfig.AudioEncoding.FLAC,
sample_rate_hertz=16000,
language_code='de-DE')
# [START speech_python_migration_async_response]
operation = client.long_running_recognize(config, audio)
# [END speech_python_migration_async_request]
print('Transcribing your local audio file...')
response = operation.result(timeout=1800)
# Each result is for a consecutive portion of the audio. Iterate through
# them to get the transcripts for the entire audio file.
for result in response.results:
# The first alternative is the most likely one for this portion.
print(u'Transcript: {}'.format(result.alternatives[0].transcript))
print('Confidence: {}'.format(result.alternatives[0].confidence))
# [END speech_python_migration_async_response]
# [END speech_transcribe_async]
# [START speech_transcribe_async_gcs]
def transcribe_gcs(gcs_uri):
"""Asynchronously transcribes the audio file specified by the gcs_uri."""
from google.cloud import speech
from google.cloud.speech import enums
from google.cloud.speech import types
client = speech.SpeechClient()
audio = types.RecognitionAudio(uri=gcs_uri)
config = types.RecognitionConfig(
encoding=enums.RecognitionConfig.AudioEncoding.FLAC,
sample_rate_hertz=48000,
language_code='de-DE')
operation = client.long_running_recognize(config, audio)
print('Transcribing your cloud-stored audio file...')
response = operation.result(timeout=1800)
# Each result is for a consecutive portion of the audio. Iterate through
# them to get the transcripts for the entire audio file.
for result in response.results:
# The first alternative is the most likely one for this portion.
print(u'Transcript: {}'.format(result.alternatives[0].transcript))
print('Confidence: {}'.format(result.alternatives[0].confidence))
# [END speech_transcribe_async_gcs]
if __name__ == '__main__':
parser = argparse.ArgumentParser(
description=__doc__,
formatter_class=argparse.RawDescriptionHelpFormatter)
parser.add_argument(
'path', help='File or GCS path for audio file to be recognized')
args = parser.parse_args()
if args.path.startswith('gs://'):
transcribe_gcs(args.path)
else:
transcribe_file(args.path)8. Run your code
Now that you created a project, successfully downloaded an audio file and the code that is needed to run the voice analysis, return to the Terminal and run the program:
python GoogleSpeech4.py HelloWorldSpeech.flac9. Monitor requests to the API
Open this dashboard to see if you are actually hitting the API when executing the code. When requests are send, the graphs should spike. They even do so if the API can’t deliver a result:
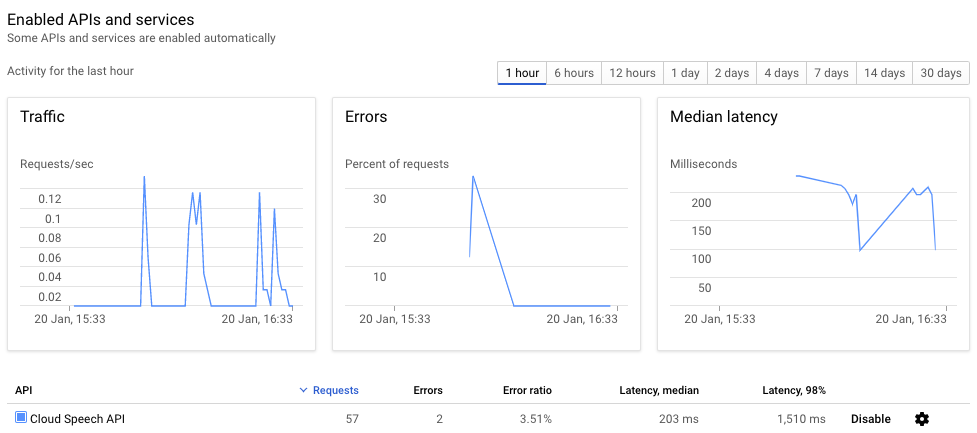
10. View the result of your request

After some waiting time, the results of the request will be visible in the terminal. Looking at the output, there will be lines for “Transcript” and “Confidence”.
- Transcript: Is the output of the text that the model returns (what the machine understood from the audio file).
- Confidence: Is a value between 0-1 that the api returns for each transcription that (assumptively) equals the confidentiality/accuracy of the model in the prediction it made (how sure the machine is that it understood correctly).
In the Google Speech API documentation it is already stated that this value might not be shown anymore at some point (or just return 0.0).
Transcribe interviews that are longer than 1 minute
The above will work for all files until the 1 min mark. For files longer than that, we need to upload the file to the Google Cloud Storage so that the algorithm can pick it up from there. For that, continue with step 10:
11. Create a Google Cloud Storage Account
In order to have longer audio files transcribed, we need to upload them to a bucket in the Google Cloud Storage. This can be done in several ways. One of them involves using the web interface;
- Go to https://console.cloud.google.com/storage/ and create a bucket with a unique name (unique to Google Cloud Storage Accounts)
- Use a location close to you (US/EU/etc.)
- Select ‘multi regional’ as your default storage class
- Assign yourself as the owner of the bucket
12. Upload file to Google Cloud Storage
Simply drag and drop your file into the Google Cloud Platform Storage browser. Once the file is uploaded, Google Cloud creates a unique URL to it. We will need this exact URL to tell our python script where it can find the file that ha to be transcribed.
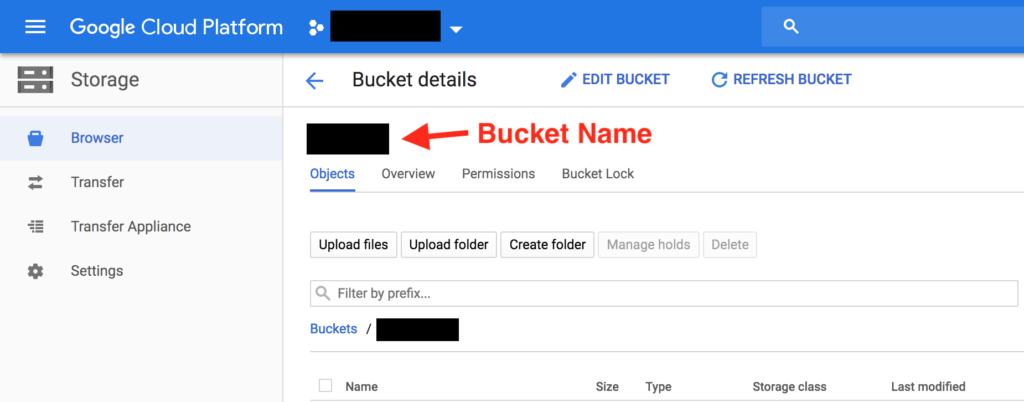
13. Run the Script by providing the new location
The file is now available in the Google Cloud Storage and we can re-run the python script to get the cloud stored audio file transcribed. We need to build the URL to the storage for that like this:
- Structure: gs:// + /”Bucket name” + “File Name” + .”File Ending”
- Example: gs://mybucket/myfile.flac
Run this command in the terminal (with the adjusted filename) in order to get a transcription.
python3 GoogleSpeech4.py gs://mybucket/myfile.flac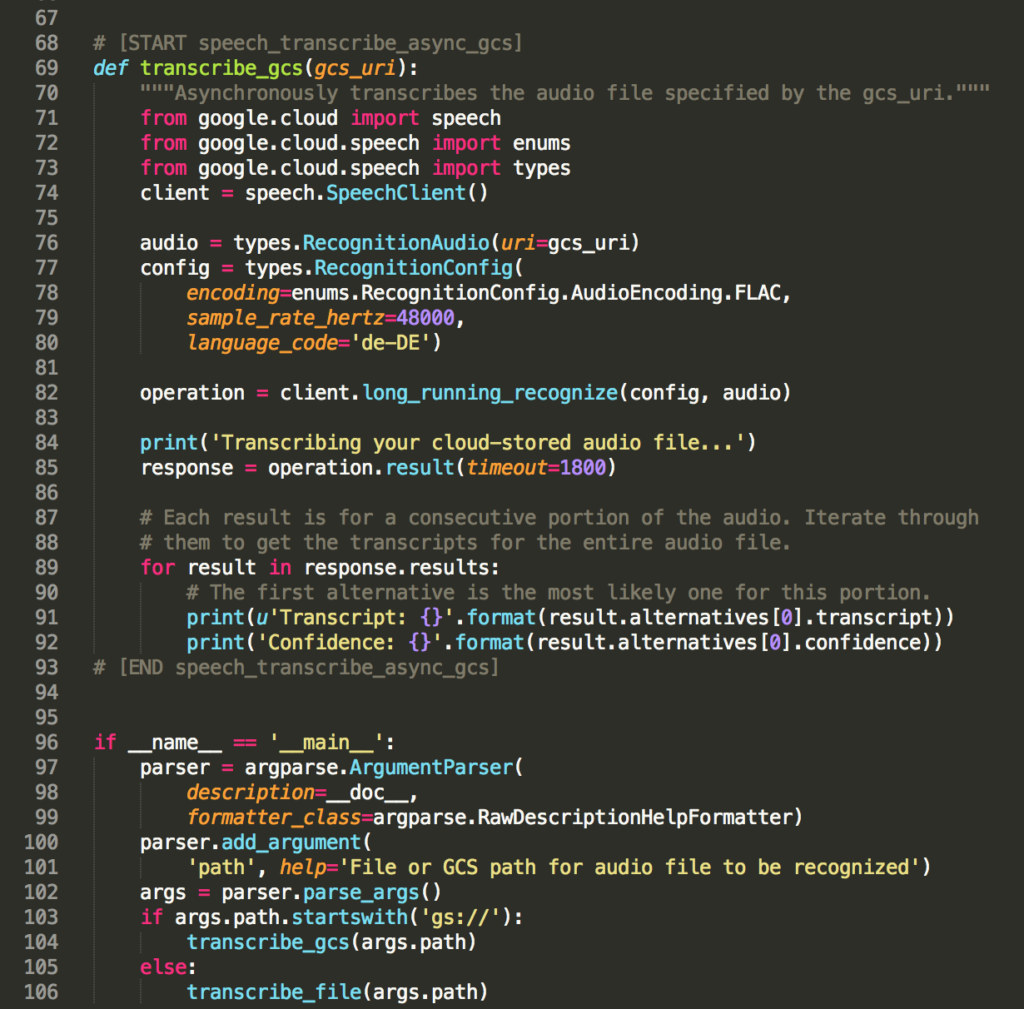
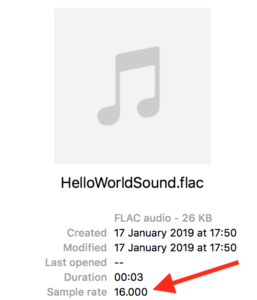
Make sure that you adjust the language, bit sampling rate and timeout based on your audio files specifics. The bit sampling rate can be found by right clicking the file on mac, then click get info.
I hope this tutorial helps you to take first steps with the Google Cloud Speech API and Google Cloud Storage.
14. Debugging & Error Messages
I’m trying to collect Error messages that one might encounter during the process. Please leave a comment with the error message or hint about what I can improve in the tutorial. I’m trying to answer all of the questions in the article.
Google Cloud Credentials missing
The error below will get triggered when Google Cloud didn’t authenticate the computer yet. This can for example happen due to a change of credentials or change of credentials location.
This can be fixed by re-running step 4 (Authenticate your machine with the Cloud).
Traceback (most recent call last):
File "GoogleSpeech4.py", line 103, in <module>
transcribe_gcs(args.path)
File "GoogleSpeech4.py", line 73, in transcribe_gcs
client = speech.SpeechClient()
File "/usr/local/lib/python3.7/site-packages/google/cloud/speech_v1/gapic/speech_client.py", line 144, in __init__
address=self.SERVICE_ADDRESS, channel=channel, credentials=credentials
File "/usr/local/lib/python3.7/site-packages/google/cloud/speech_v1/gapic/transports/speech_grpc_transport.py", line 61, in __init__
channel = self.create_channel(address=address, credentials=credentials)
File "/usr/local/lib/python3.7/site-packages/google/cloud/speech_v1/gapic/transports/speech_grpc_transport.py", line 92, in create_channel
address, credentials=credentials, scopes=cls._OAUTH_SCOPES
File "/usr/local/lib/python3.7/site-packages/google/api_core/grpc_helpers.py", line 177, in create_channel
credentials, _ = google.auth.default(scopes=scopes)
File "/usr/local/lib/python3.7/site-packages/google/auth/_default.py", line 294, in default
credentials, project_id = checker()
File "/usr/local/lib/python3.7/site-packages/google/auth/_default.py", line 165, in _get_explicit_environ_credentials
os.environ[environment_vars.CREDENTIALS])
File "/usr/local/lib/python3.7/site-packages/google/auth/_default.py", line 89, in _load_credentials_from_file
'File {} was not found.'.format(filename))Wrong Bit Sampling Rate in file
One of the issues that you might encounter is that the file you submit to the API has a different Bit Sampling Rate than what the python script is stating. In that case, either adjust the python script by changing the following line to match the sampling rate of the audio file (look at step 12 to learn how to find out the current bit sampling rate of the audio file):
sample_rate_hertz=48000,
The other method to fix this is by converting the file into a different bit sampling rate. This is not advised since it can harm the quality of transcription when changing. If this is still an option, use one of the many free converters online:
Its also clearly stated in the error message what bit sampling rate is stated in the code and which rate the audio file is using.
Traceback (most recent call last):
File "/usr/local/lib/python3.7/site-packages/google/api_core/grpc_helpers.py", line 57, in error_remapped_callable
return callable_(*args, **kwargs)
File "/usr/local/lib/python3.7/site-packages/grpc/_channel.py", line 550, in __call__
return _end_unary_response_blocking(state, call, False, None)
File "/usr/local/lib/python3.7/site-packages/grpc/_channel.py", line 467, in _end_unary_response_blocking
raise _Rendezvous(state, None, None, deadline)
grpc._channel._Rendezvous: <_Rendezvous of RPC that terminated with:
status = StatusCode.INVALID_ARGUMENT
details = "sample_rate_hertz (16000) in RecognitionConfig must either be unspecified or match the value in the FLAC header (48000)."
debug_error_string = "{"created":"@1549053032.353849000","description":"Error received from peer","file":"src/core/lib/surface/call.cc","file_line":1036,"grpc_message":"sample_rate_hertz (16000) in RecognitionConfig must either be unspecified or match the value in the FLAC header (48000).","grpc_status":3}"
>
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "GoogleSpeech4.py", line 104, in <module>
transcribe_gcs(args.path)
File "GoogleSpeech4.py", line 82, in transcribe_gcs
operation = client.long_running_recognize(config, audio)
File "/usr/local/lib/python3.7/site-packages/google/cloud/speech_v1/gapic/speech_client.py", line 324, in long_running_recognize
request, retry=retry, timeout=timeout, metadata=metadata
File "/usr/local/lib/python3.7/site-packages/google/api_core/gapic_v1/method.py", line 143, in __call__
return wrapped_func(*args, **kwargs)
File "/usr/local/lib/python3.7/site-packages/google/api_core/retry.py", line 270, in retry_wrapped_func
on_error=on_error,
File "/usr/local/lib/python3.7/site-packages/google/api_core/retry.py", line 179, in retry_target
return target()
File "/usr/local/lib/python3.7/site-packages/google/api_core/timeout.py", line 214, in func_with_timeout
return func(*args, **kwargs)
File "/usr/local/lib/python3.7/site-packages/google/api_core/grpc_helpers.py", line 59, in error_remapped_callable
six.raise_from(exceptions.from_grpc_error(exc), exc)
File "<string>", line 3, in raise_from
google.api_core.exceptions.InvalidArgument: 400 sample_rate_hertz (16000) in RecognitionConfig must either be unspecified or match the value in the FLAC header (48000).
I always get this message when executing the code:
Traceback (most recent call last):
File “GoogleSpeech4.py”, line 103, in
transcribe_gcs(args.path)
File “GoogleSpeech4.py”, line 73, in transcribe_gcs
client = speech.SpeechClient()
File “/usr/local/lib/python3.7/site-packages/google/cloud/speech_v1/gapic/speech_client.py”, line 144, in __init__
address=self.SERVICE_ADDRESS, channel=channel, credentials=credentials
File “/usr/local/lib/python3.7/site-packages/google/cloud/speech_v1/gapic/transports/speech_grpc_transport.py”, line 61, in __init__
channel = self.create_channel(address=address, credentials=credentials)
File “/usr/local/lib/python3.7/site-packages/google/cloud/speech_v1/gapic/transports/speech_grpc_transport.py”, line 92, in create_channel
address, credentials=credentials, scopes=cls._OAUTH_SCOPES
File “/usr/local/lib/python3.7/site-packages/google/api_core/grpc_helpers.py”, line 177, in create_channel
credentials, _ = google.auth.default(scopes=scopes)
File “/usr/local/lib/python3.7/site-packages/google/auth/_default.py”, line 294, in default
credentials, project_id = checker()
File “/usr/local/lib/python3.7/site-packages/google/auth/_default.py”, line 165, in _get_explicit_environ_credentials
os.environ[environment_vars.CREDENTIALS])
File “/usr/local/lib/python3.7/site-packages/google/auth/_default.py”, line 89, in _load_credentials_from_file
‘File {} was not found.’.format(filename))
Hi,
I just used this tutorial to set up everything for transcribing my interviews and everything works fine (after some hours of work 🙂
Now I am wondering how to specify the output path/create text files from the transcript because the result is not really useful in the console. I was trying to change the code of the .py file but I wasn´t able to figure it out yet because I´ve never worked with Python before. I would really appreciate your help on this and maybe it would be cool to add this step to the tutorial as other people could have the same issues.
Thank you very much for your help!
Cheers,
Bastian
Hey Bastian, sorry for coming back so late – your message slipped through and I’ve just seen it now.
It surely is some work (I’m also not very proficient in python and often work after trial and error).
In case you’re still playing with the API and work on the project and havent figured out yet, I’d like to try to assist.
I need to check my code again – getting an output file was a single line of python if I remember right.
If you figured it out already, please feel free to post it here. I’ll see if I can find it 🙂
Hey Julian!
I just recently found your tutorial! It’s awesome. Thank you for writing it!
I’ve also come across this issue. I just wanted to ask if you ever found the line of code that you were talking about or not?
I just started looking into file handling and I’m not entirely sure what I’m doing exactly, haha. I’ve just started coding! Would love to know how you handled it. Thanks again!
Ed
Im getting the following error when running the script with the helloworld.flac.
Traceback (most recent call last):
File “transcribe_async.py”, line 110, in
transcribe_file(args.path)
File “transcribe_async.py”, line 43, in transcribe_file
audio = speech.RecognitionAudio(content=content)
AttributeError: ‘module’ object has no attribute ‘RecognitionAudio’
Any idea what I did wrong? I copied the transcribe_async.py file, adjusted the 3 params and setup all google cloud things. Now the terminal gives me this error.
Thanks!
Sam